序
源于在开发了拖拉机跟打器之后,就有人问过,跟打器的词语标记是怎么算出来的,找了个时间写下这篇文章,整篇文章建立在java的基础上。 该文章中只提思路给打算自己创造跟打器或者对词语提示有兴趣的读者,不涉及到主要源码。
拖拉机跟打器词语标记算法
1)对码表按行读取,并以tab键为分隔提取出中文词条和英文编码,命名为,ch和bm(扣脚命名莫嫌弃)
2)将码表按照词条长度分类进入不同的HashMap中,并用ArrayList将多个HashMap<String,String>串起来。
3)运算第一次循环,将获取的文章遍历,并从长度最长开始匹配词条,大概就是如下图,如果到某个位置与词语$\color{完全匹配} $,则将该词语$\color{占用} $下标记录,并从步骤2中存入的hashmap提取出该词语的编码长度,再将该文拥有的词按$\color{编码长度} $进行分类。

假设,第一次循环中获取匹配词语的占用位置如下图(红色),当在以后的回塑循环中(绿色),就要进行回避这些位置的匹配。并将词语对应编码长度放入对应的分类,往后以此类推。
回塑时避让占用位置
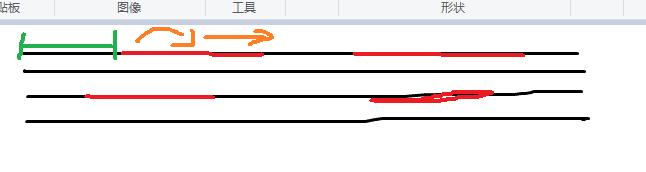
遍历避让占用位置
-15717ea99efe4b07a61b6358df11ae57.png)
4)当你将所有长度的可能词条都遍历了一遍,我现在设定的是最长词条为13,即只遍历文章13遍(越到后面其实回避做的更多)。而存入HashMap中,使匹配消耗资源不至于过大。走完13遍之后,我们就可以根据我们之前以编码长度来分类的占用位置来进行标记颜色。
那么可以得知,我们一共创建了 用于存储码表关系的1个List中和对应最长词条长度n个Map 用于记录标色的对应目标文章中的最长词条编码长度m个List (在实际操作中创建的可能比预想的更多,看每个人的思路) 对于非首选的其他,次选,三选,四选。可以识别编码的最后一位 这大概只讲思路不详细深入,希望读者自己多加研究。
理论编码(类似极速赛码)
对于理论编码,只是在词语标记的基础上增加了一些对编码的操作,其实也非常简单。说说我的做法
1)在词语标记的基础上,再创建一个HashMap<int,String>,命名为bianma,在词语标记步骤3与步骤4的遍历中,匹配到词语的占用位置后,将占用的首位放入key,对应的编码放入value。
2)等所有的遍历做完,做一个循环for(i从0到目标文章.length-1),for内执行,得出的showstr就是整篇文章的理论编码
for(int i=0;i<c.length;i++){
if(Tips.bianma.containsKey(i)){
showstr.append(Tips.bianma.get(i));
}
}
算法缺点
在面对长词对短词的场合下,可以达到最佳的词语提示 例如:怎么样 这个时候就会标记“怎么样”,并不会单独标记“怎么”。
但在某些特定的同编码长度组合,有可能并不是最佳标记与最短码长打法。 例如:上身体 先不说这个诡异的词,但是这个组合在我的词库中是有两个词的 “上身”,“身体”
而“上身”编码为“uhuf”,“身体”编码为“ut”,这个时候,标记会标记“上身”的四码词颜色,并不是标记“身体”的二简颜色,最终获得的理论编码为“uhufti_”而不是理想的“uh_ut_”
算法复杂测试
在进行压力测试,导入了10w字的文章大概载了30秒。

