序
在之前写的非动态规划的词语提示算法,也进行过优化。 但还有许多缺点需要使用动态规划重写实现,最主要有两方面:
1、多字叠词无法实现提示最短编码打法。
2、算法压力测试结果堪忧。
实现过程
一、分析需求进行准备
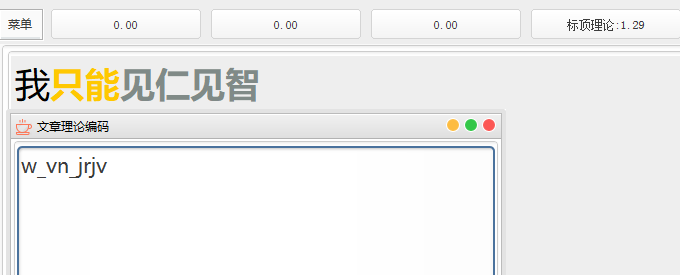
1、载文时计算出最短编码,并显示在跟打器
无论怎么叠词,总是能得出最短编码和最短打法显示,显示时需要根据不同的编码长度显示对应的词简性。(此处二简黄色,四码灰色,单字黑色)
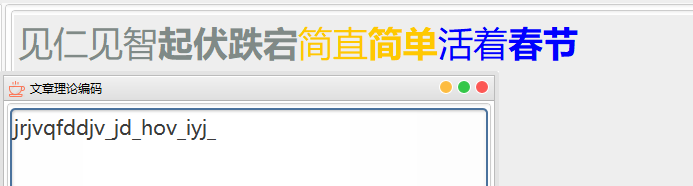
2、同类词语放在一起粗细区分
同一类型的词,如果挨在一起相同颜色会分不清是一个词还是两个,这里还需要一个粗细划分。
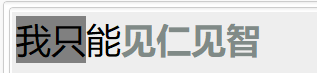
3、打过颜色变黑
词被拆单打后,被打部分显示灰色,后部无词就不再显示颜色。
4、动态显示
将词拆开后,若长词中内嵌短词,会动态再次显示出内嵌的短词,拆开显示的短词依然为最短打法提示并且对应打法的词简性更改显示颜色。

二、构建数据结构
原使用的是散列表存放键值,(存储词的起始位置,遍历文章时用该位置来当起始位置key来查询该位置的对应末尾位置value)然后中间显示颜色。
但之前在一百万字的测试下,放入数据量太大,也需要频繁的查找value,导致载文一百字需要40秒左右的时间。
所以改为构建一个数据结构下标对象SubscriptInstance类,来存放文章某位置的所有信息(上一跳,下一跳,编码,临时编码长度等,下文会讲到,这里只阐述使用结构数组subscriptInstances[article.length()]来增加效率)
数据结构类
public class SubscriptInstance {
private int next;//下一跳
private HashMap<Integer,PreInfo> preInfoMap;//上一跳
private String word;
private String wordCode;
private int type;//0单 1全 2次全 3三简 4 次三简 5二简 6次二简
private boolean useSign;
private boolean useWordSign;
private int codeLengthTemp;
public class PreInfo{
//同长度不同上跳表,用于动态词提
private HashMap<Integer,Integer> preAndType = new HashMap<Integer,Integer>();
private String wordsCode;//最短编码路径的编码
private String words;//最短编码路径的词条
PreInfo(int pre,String words,String wordsCode,int type){
this.preAndType.put(pre, type);
this.words = words;
this.wordsCode = wordsCode;
}
public HashMap<Integer,Integer> getPre(){
return preAndType;
}
public int getMinPre(){
List<Integer> list = new ArrayList<>(preAndType.keySet());
Collections.sort(list);
return list.get(0);
}
public boolean containPre(int pre){
return this.preAndType.containsKey(pre);
}
public int getType(int pre) {
return preAndType.get(pre);
}
public void addPre(int pre ,int type){
preAndType.put(pre, type);
}
getter and setter
……
}
public SubscriptInstance(int i){
next = i;
preInfoMap = new HashMap<Integer,PreInfo>();
wordCode = "";
word = "";
useSign = false;
useWordSign = false;
codeLengthTemp = 0;
}
public SubscriptInstance(int i,String word,String wordCode){
this(i);
this.wordCode = wordCode;
this.word = word;
}
public void addPre(int length,int pre,String words,String wordsCode,int type) {
if(!preInfoMap.containsKey(length))
this.preInfoMap.put(length, new PreInfo(pre,words,wordsCode,type));
else
this.preInfoMap.get(length).addPre(pre, type);
}
public PreInfo getShortCodePreInfo(){
return preInfoMap.get(codeLengthTemp);
}
public void removePre(int length){
this.preInfoMap.remove(length);
}
getter and setter
……
}
三、分析与实现
1、显色逻辑
由于在java实现显示时,必须是一个字接一个渲染,在将文章第一个字渲染为灰色时,就无法改变了。若要进行改变某个字体的颜色,就必须将显示板清空,重新将全文渲染。
显示的前提是,需要有词的类型与词的始末位置。
这里需要词性type和下一跳next
颜色对照:
| 词性 | 颜色 | type值 |
|---|---|---|
| 全 | 灰 | 1 |
| 次全 | 斜体灰 | 2 |
| 三简 | 蓝 | 3 |
| 次三简 | 斜体蓝 | 4 |
| 二简 | 黄 | 5 |
| 次二简 | 斜体黄 | 6 |
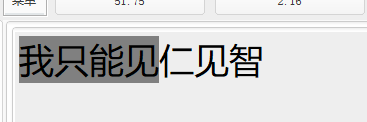
在初始化显示时,i递增来遍历文章每一个字符,并从subscriptInstance[i]取出这个位置的词性type和下一跳位置j,如果type得出是词的话,就渲染i到j的字体,然后将j赋给i实现跳过中间的下标type判断。
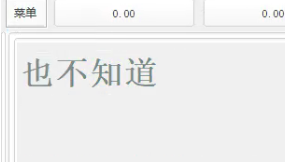
下图即为 subscriptInstance[0].setType() = 1; subscriptInstance[0].setNext = 3; 后的显示效果

2、最短编码长度
这里我通过走一遍动态规划来解释计算过程。
例:
这里需要该下标最短编码codeLengthTemp,单字编码wordCode。
ABCDEF
词:ABC,DEF,CD,ABCD。 词都是四码,单字是3码
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 0 | 0 | 0 | 0 | 0 | 0 |
下标0:
词最后一位下标:ABC为词,ABCD为词,C和D对应的下标最短编码都为0,不需要比较即可分别将两个(0+词的编码长度)填入词的最后下标。ABC最后下标为2填入0+4,ABCD最后下标为3填入0+4。
自身下标:默认下标0最短编码为0,将(0+单字A编码长度)填在下标0中。
| 下标 | ->0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 3 | 0 | 4 | 4 | 0 | 0 |
下标1:
词最后一位下标:B无任何可组词,最后将(下标0的最短编码+单字B编码长度)填入下标。
自身下标:下标1最短编码为0,不需要判断即可将(下标0的最短编码长度+单字B编码长度)填在下标1中。
| 下标 | 0 | ->1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 3 | 6 | 4 | 4 | 0 | 0 |
下标2:
词最后一位下标:CD为词,单词的最后一位D对应下标3,下标3已有最短编码,将(下标1的最短编码长度+词的编码长度)与(下标3已有的最短编码)对比,将小的填入下标3。
自身下标:下标2已有最短编码4,这时不能直接将(下标1的最短编码长度+单字C的编码长度)填入下标3,需要(下标1的最短编码长度+单字C的编码长度)与(下标2已有最短编码)对比,将小的替换下标2。
| 下标 | 0 | 1 | ->2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 3 | 6 | 4 | 4 | 0 | 0 |
下标3:
之后就是重复判断。
词最后一位下标:DEF为词,填F位为(DEF编码长度+下标2最短编码)
自身下标:下标3自身不变。
| 下标 | 0 | 1 | 2 | ->3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 3 | 6 | 4 | 4 | 0 | 8 |
下标4:
词最后一位下标:无词,不填。
自身下标:原为0,填7。
| 下标 | 0 | 1 | 2 | 3 | ->4 | 5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 3 | 6 | 4 | 4 | 7 | 8 |
下标5:
词最后一位下标:最后一位,不可组词。
自身下标:原为8,对比(7+3),不替换。
| 下标 | 0 | 1 | 2 | 3 | 4 | ->5 |
|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F |
| 最短编码长度 | 3 | 6 | 4 | 4 | 7 | 8 |
通过动态规划就能计算出ABCDEF在特定词库下的最短编码长度。
3、提供显色条件(上一跳与下一跳)
由于在动态规划中,在没有彻底跑完整个过程的情况下,是确保正确性的。就是说,在遍历的过程中,你无法知道当前的下一跳。这个时候需要使用上一跳在规划过程跑完之后,倒着将下一跳添加上去。
由于下面还需要做动态显示,所以需要从记录到达最后一字符的所有路径。(不懂的同学我也无法写清楚了),所以需要preInfoMap,记录所有不同最短编码长度上一跳的信息`
HashMap<Integer,PreInfo> preInfoMap`,但也难免会出现不同路径却能导致相同最短编码的结果。
例: “也不知道”的路径
| 编码 | 最后下标codeLengthTemp | 上一跳下标 |
|---|---|---|
| ybvd | 4 | 0 |
| ye_bvd_ | 7 | 1 |
| yebuvd_ | 7 | 2 |
| ye_b_vd_ | 8 | 2 |
这就会导致散列覆盖,动态词提就会将覆盖掉上一跳下标为1的词语提示。导致打完“也”字时,由于“ye_bvd_”打法被“yebuvd_”覆盖,所以不会显示“不知道”的蓝色标记。(不懂的同学我也无法写清楚了)。
HashMap<Integer,Integer> preAndType = new HashMap<Integer,Integer>()
使用PreInfo中的字段,来记录最后相同编码长度,但上一跳不同的词性和上一跳下标。
这里称遍历位置为“跳点”,上一跳为“落点”,通过使用“codeLengthTemp”来寻找最短路径的“落点”。我们从“跳点”跳到“落点”后,将“落点”的下一跳next设置为“跳点”。如果从最后一字符一直这么往前跳到文章首部,我们就可以从文章首部开始使用next和type来标记颜色和范围了。
若不仅仅是只将“codeLengthTemp”寻找最短路径,而是将所有可能的上一跳记录下来后,再往上跳,我们就可以实现动态词语提示。但这个记录所有上跳的操作,需要在记录完最佳路径的上跳后再执行,并且在添加所有上一跳记录的时候,我们需要添加以下限制。
1)如果不是最佳路径的词语,我们不能将起始点为未被最佳路径词语覆盖且末尾点已被最佳路径覆盖的位置添加到记录中。
举例: ABCD,“A”“BCD”,拆法为最佳路径。但“AB”有词,就不能将B的上一跳为A记录下来。这样会使在遍历时优先显示“AB”,并将下标跳到C。跳过“BCD”的显示。
2)如果不是最佳路径的词语,我们将已被最佳路径的词语设置为词语起始点的位置记录为起始点。
举例: ABCD,“ABC”“D”与“AB”“CD”。这时如果有多个起始点,会使“A”有多个下一跳。不允许这个冲突存在。
所以 添加字段useWordSign,为该下标是否为最佳编码起始点。 添加字段useSign,为该下标是否为词语最佳路径词语覆盖点。
4、最短编码
添加最佳编码字段:PreInfo.wordsCode。对应的每个最佳上跳都有一个上跳代表的最佳编码。每次下跳时取出该点的上跳最佳编码并累加,即可得到最后的全文最短编码。
5、粗细区分
准备工作:创建六个链表存放不同的词性的起始下标位置链表,将已存在数组subscriptInstance[i]文章遍历,将type取出,如果取出的type在1-6的范围内,说明这为一个词,将该下标添加进对应的词性链表。最后将链表从大到小排序(排序是为了动态显示时粗细不变化[不解释了自己想吧亲hhh])。
跟打过程:从用户跟打下标位置开始,遍历该页的每个位置是否在六个链表中,并使用IndexOf取出位置来%2,0显粗,1显细。
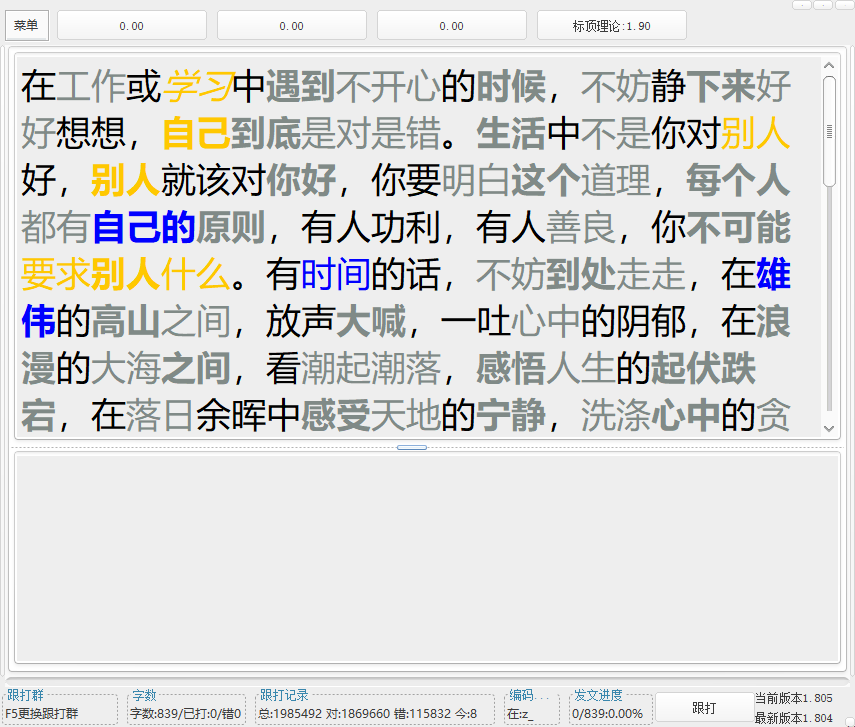
压力测试结果对比
参数:
电脑环境:i5 9400f 16G内存
词库数量:10万5千
文章:倚天屠龙记(全文95万)这里只测试了部分字数
系统:win10
旧算法与各跟打器对比

新算法与各跟打器对比


