在fps中经常会遇到“怪东西”,是否听说过班加罗尔的一句话:女士们,自动瞄准简直就是天方夜谭。
本篇文章就教大家如何利用深度学习,从零开始,搞一搞ai自动瞄准。
本文篇幅较长,可按目录跳过观看。
- 搭建yolov5运行环境
- 训练自己的模型
- 利用yolov5编写自动瞄准
- 拟人移动鼠标
- 双机架构
一、搭建yolov5运行环境
硬件前提:
- n卡,需要利用cuda
软件准备:
-
更新最新的n卡驱动,安装cuda11.7,安装cudnn,安装TensorRT
-
git代码管理,官网下载
-
基于anaconda来配置python虚拟环境,anaconda官网下载
-
pycharm,官网下载
1、驱动更新
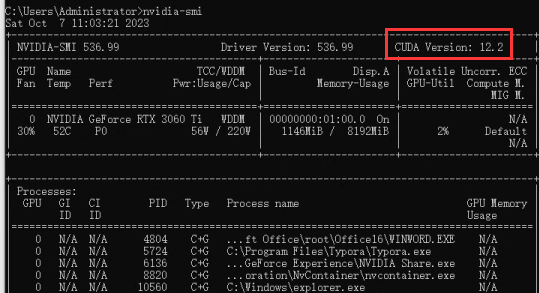
n卡面板更新到最新驱动,打开cmd输入命令:nvidia-smi
红框内显示的是最大支持cuda版本,大于11.7即可
2、安装cuda相关环境
下载cuda11.7,下载cudnn,下载TensorRT,三个文件下载后会有以下三个文件。

-
安装cuda11.7,默认安装,选择自定义安装全勾选后全部默认。默认会被安装在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7下
-
解压cudnn-windows-x86_64-8.9.2.26_cuda11-archive.zip和cudnn-windows-x86_64-8.9.2.26_cuda11-archive.zip
-
解压TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8.zip
-
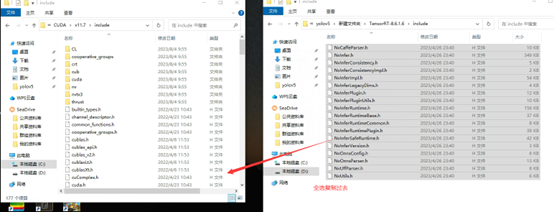
把\include里面的所有文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include中
-
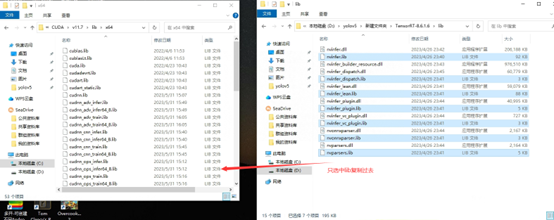
\lib 中所有以lib结尾文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\x64下
-
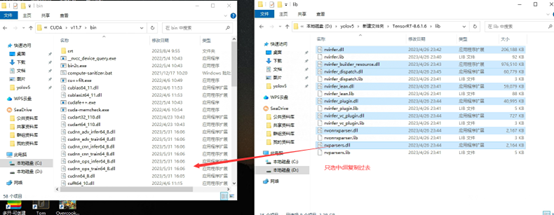
\lib 中所有以dll结尾文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin下
-
将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib\x64添加到环境变量中,确保有以下三个环境变量

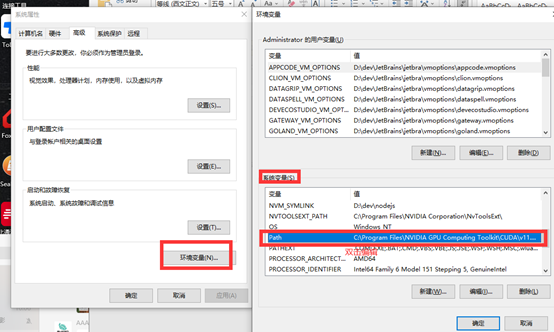


-
重启电脑,Cmd运行命令 nvcc –version 出现以下安装cuda成功
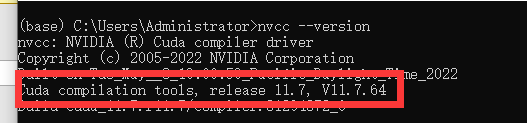
3、安装python环境
基于anaconda来配置python虚拟环境,anaconda官网下载,anaconda安装一路默认就行了。没什么好说的。
检查是否正确安装好anaconda。cmd输入 conda -V。若出现版本号,则安装成功。

如果出现conda命令不存在,需要在环境变量添加:anaconda安装路径\condabin
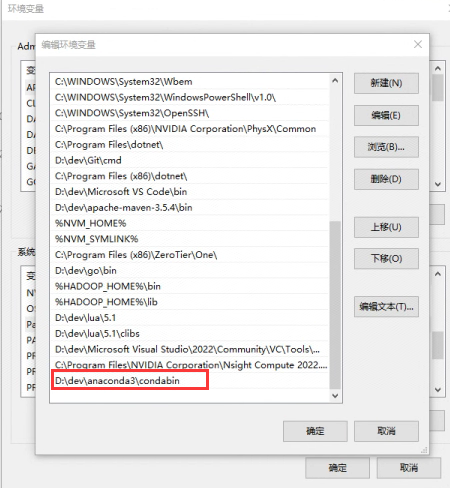
初始化python环境,我们选择python3.9来初始化环境(不要使用最新的python版本,labelimg在当前最高支持py3.9)。cmd中输入conda create -n ai-yolov5 python=3.9 -y,创建一个命名为ai-yolov5的python3.9环境。出现以下提示,则安装完毕。

根据提示,cmd中输入conda activate ai-yolov5,切换到ai-yolov5虚拟环境后,python --version会输出Python版本。

至此基于anaconda配置python环境完成。
4、配置yolov5运行环境
git代码管理,官网下载,安装全默认即可。
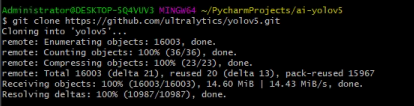
在一个你想要放代码的文件夹中,使用gitclone代码,git clone https://github.com/ultralytics/yolov5.git
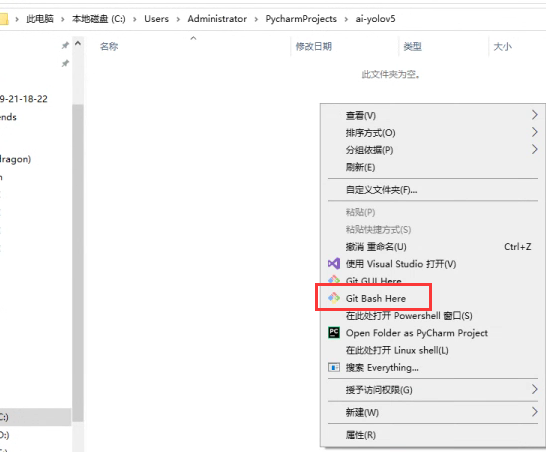

使用pycharm打开该文件夹,打开后,配置python虚拟环境
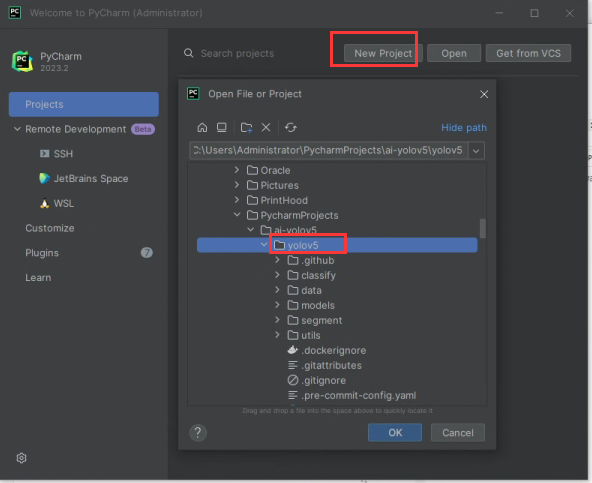
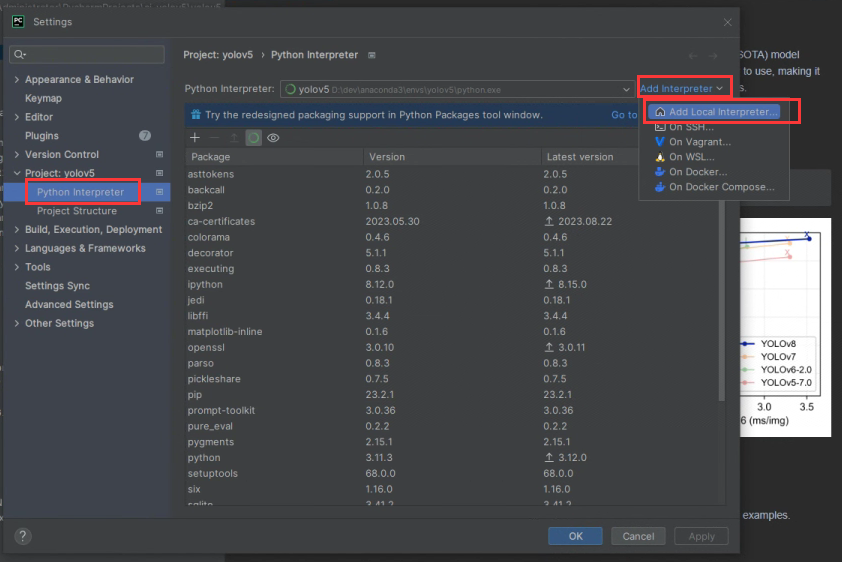
添加本地环境时,选择conda environment,conda executable选择你conda的安装目录下的\condabin\conda.bat,点击Load Environments读取已有的虚拟环境。选择已有的环境,下拉框选择我们刚刚创建的基于python3.9的ai-yolov5
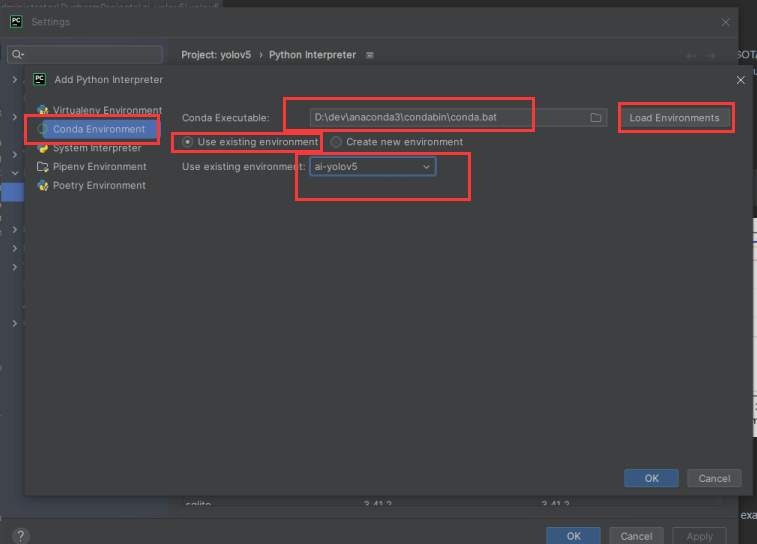
点击ok后,能看到该环境下已有的依赖包,点击Apply或ok即可。
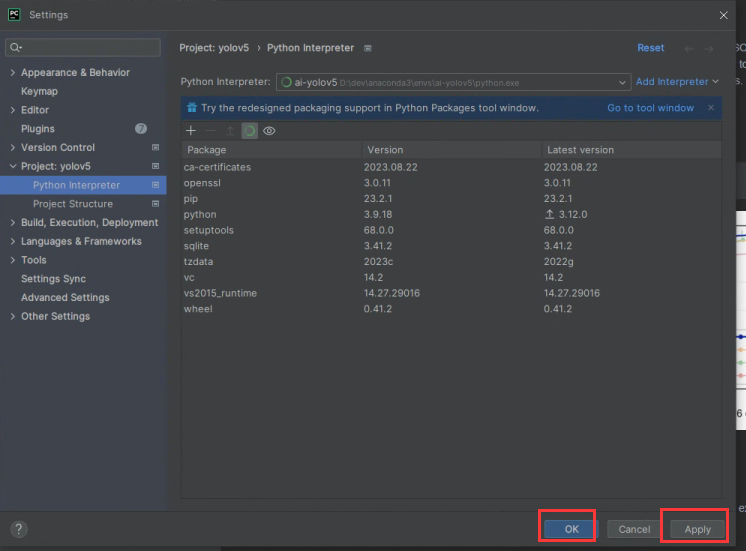
选择成功后,返回到项目,右下角看到环境已切换。

在pycharm终端中输入pip install -r requirements.txt安装依赖
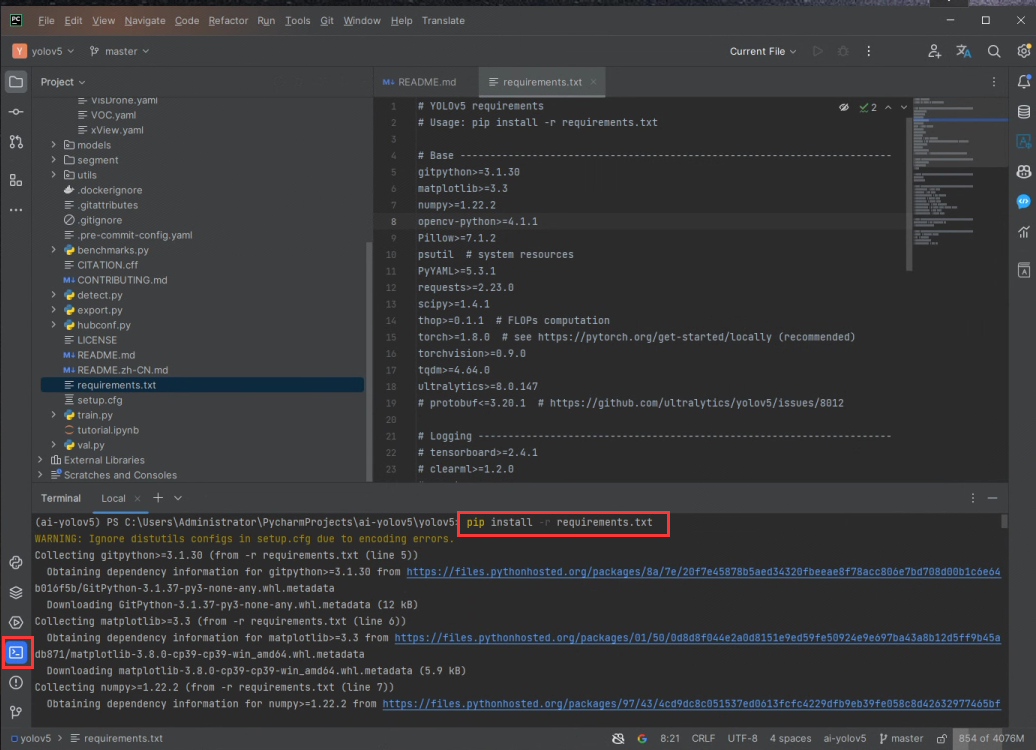

其中注意有几个依赖是需要根据系统环境进行变更的, pytorch版本cuda版本对照。
本文使用的是cuda11.7版本,对应需要安装cu117-cp39版本的依赖,pytorch依赖下载,找到以下几个whl文件并下载。
torch-2.0.0+cu117-cp39-cp39-win_amd64.whl
torchaudio-2.0.0+cu117-cp39-cp39-win_amd64.whl
torchvision-0.15.0+cu117-cp39-cp39-win_amd64.whl
先卸载原来requirements.txt中安装的依赖pip uninstall torchvision torchaudio torch -y
再安装这三个whl文件
pip install torch-2.0.0+cu117-cp39-cp39-win_amd64.whl
pip install torchaudio-2.0.0+cu117-cp39-cp39-win_amd64.whl
pip install torchvision-0.15.0+cu117-cp39-cp39-win_amd64.whl
在TensorRT压缩包内,python文件夹下还有三个whl需要安装
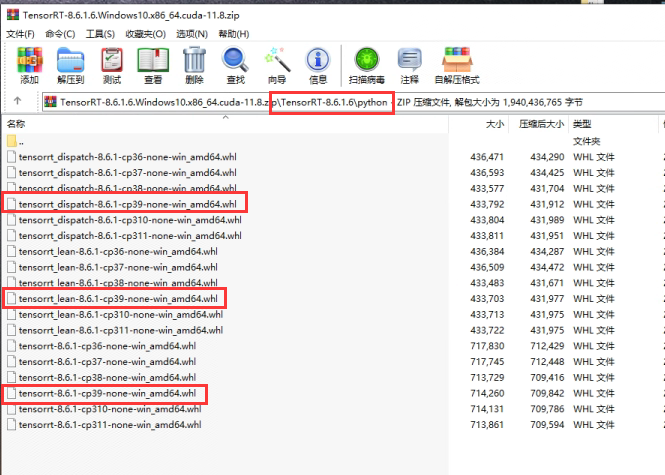
pip install tensorrt_dispatch-8.6.1-cp39-none-win_amd64.whl
pip install tensorrt_lean-8.6.1-cp39-none-win_amd64.whl
pip install tensorrt-8.6.1-cp39-none-win_amd64.whl
5、尝试运行yolov5
右键项目根目录下的train.py,点击Run train会使用默认参数来尝试训练模型
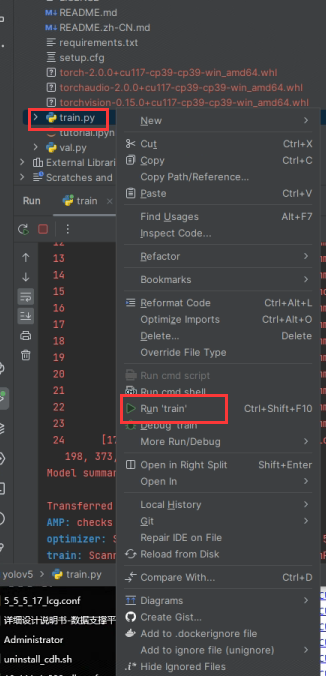
默认会使用data\coco128.yaml这个配置文件去训练,会自动下载coco数据集进行训练。
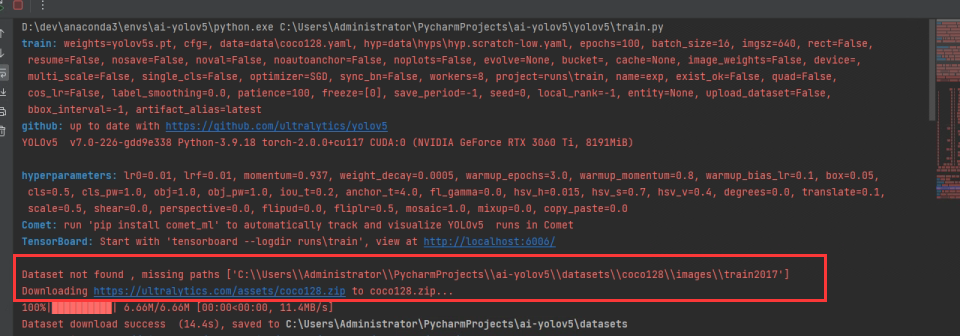
下载完数据集后,会出现即将启用多少个epochs,和正在运行的epoch,这说明环境配置没有问题,yolov5正在训练模型,接下来等待程序结束即可。
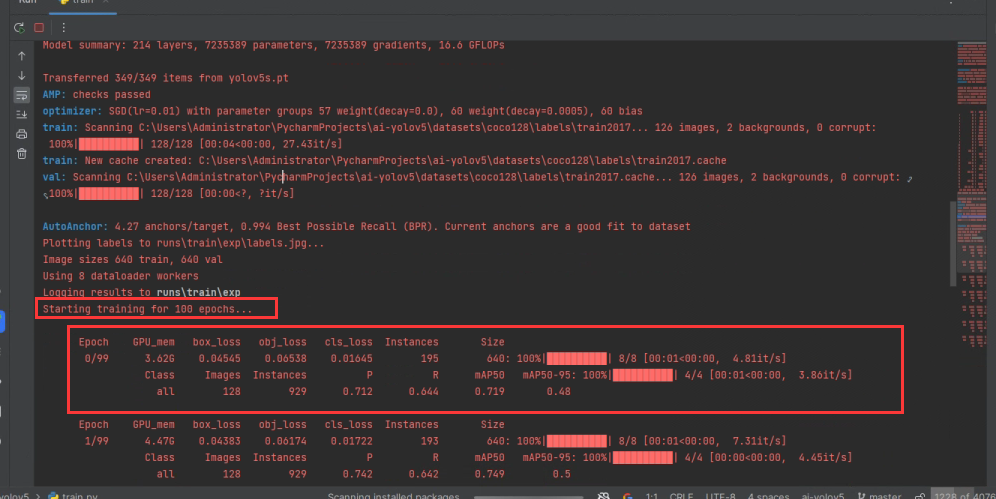
100个epochs跑完后会打印保存pt文件的路径,和pt文件里class的信息,训练结果被保存在runs\trins\exp中。
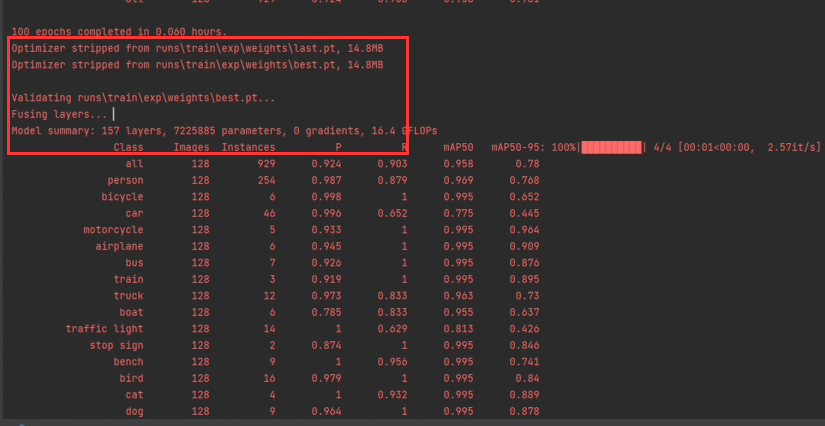
这个时候就可以,运行detect来快速得到该模型的测试检测结果。
默认参数启动,会使用data\images作为源,获取该文件的所有图片去执行检测。会打印每张图片的检测信息。
第一张图片bug.jpg中有4个人,1个车,耗时43.6ms
第二张图片zidanejpg中有2个人,2个领带,耗时42.0ms

检测结果保存在runs\detect\exp中,在该目录中我们可以看到两张被标记过的图片,这样yolov5就算是成功运行了。


至此整个yolov5的运行环境搭建已经完成了,接下来是要去了解yolov5中的配置文件,各种超参含义,怎么训练自己的模型等。
二、训练自己的模型
1 、了解数据集的文件结构
一般来说,我们的训练集会有以下目录,训练->验证->测试。一般数据集三部分的比例为8:1:1,其中images用于存放图片,labels用于存放标注图片的描述文件,其中labels/xx.txt是用来描述images/xx.jpg的标注信息的,其他文件以此类推。
dataset #(数据集名字)
├── images
├── train
├── xx.jpg
├── val
├── yy.jpg
├── test
├── zz.jpg
├── labels
├── train
├── xx.txt
├── val
├── yy.txt
├── test
├── zz.txt
打开我们刚刚在上面下载的coco128数据集。处于项目的同一目录的dataset文件夹下。

可能测试训练为了简化,该文件的目录只有train目录。
dataset\coco128 #(数据集名字)
├── images
├── train2017
├── xx.jpg
├── labels
├── train2017
├── xx.txt
2、标注工具的使用
1)安装标签工具
安装标注工具:pip install labelimg

安装成功后,在项目命令行中输入labelimg即可打开标注工具,会弹出一个这样的窗口。

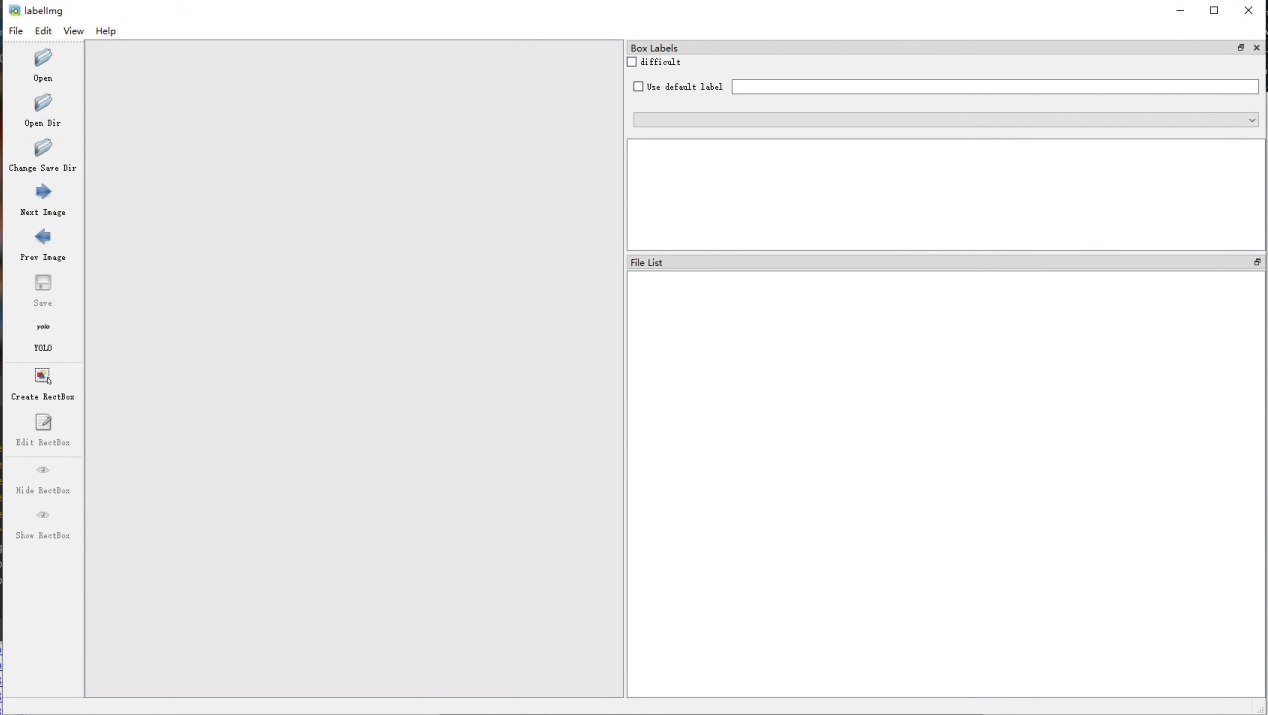
其中Open Dir是打开图片,Open Save Dir是打开标注文件的,以coco128为例:
选择images文件夹
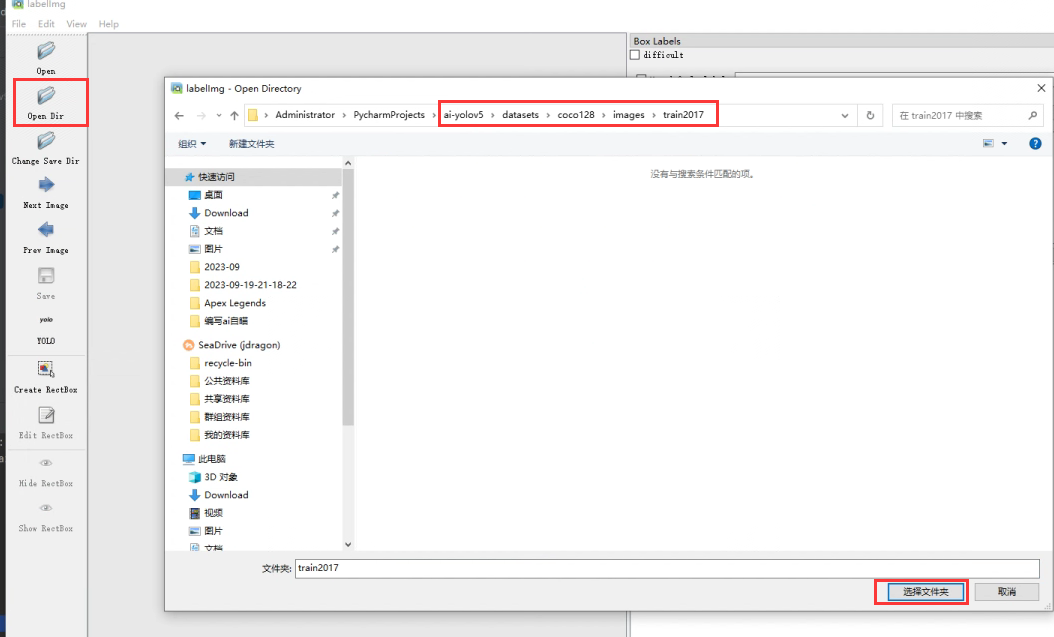
选择labels文件夹
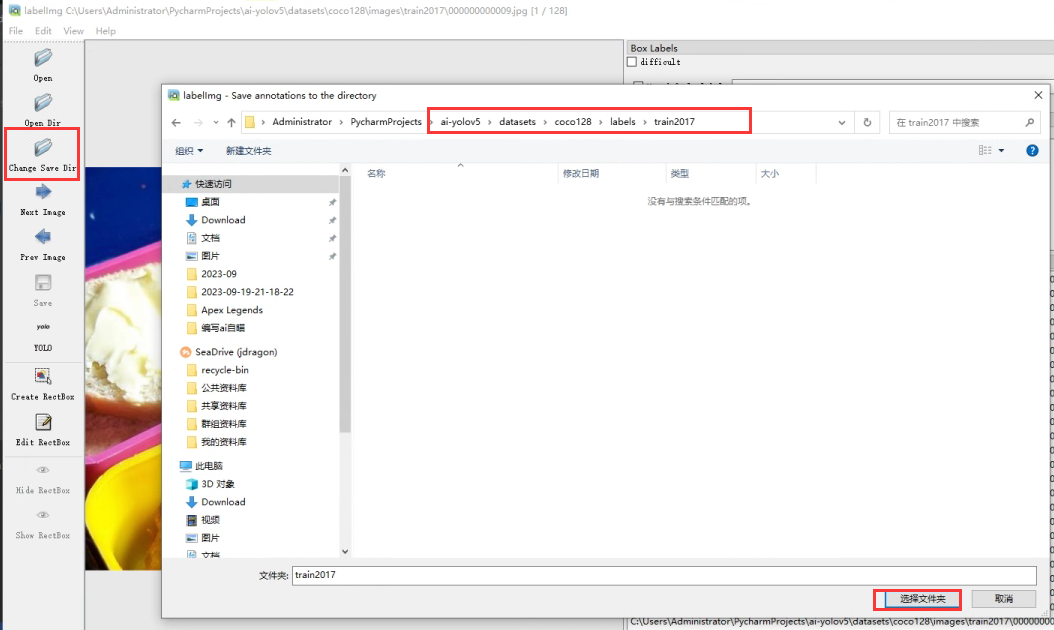
在完成选择后,会出现报错:No such file or directory,并直指labels/train2017/classes.txt
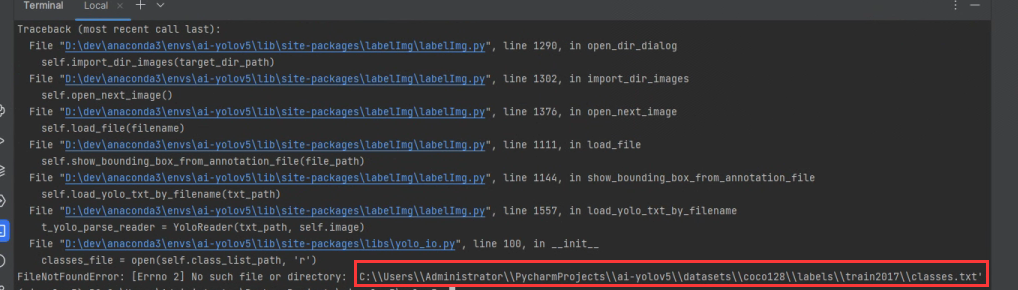
这个文件是用来存放我们这个lables文件夹下的所有class的,我们下载的coco数据集是没有这个文件的。我们可以在项目中的data\coco128.yaml中获取。
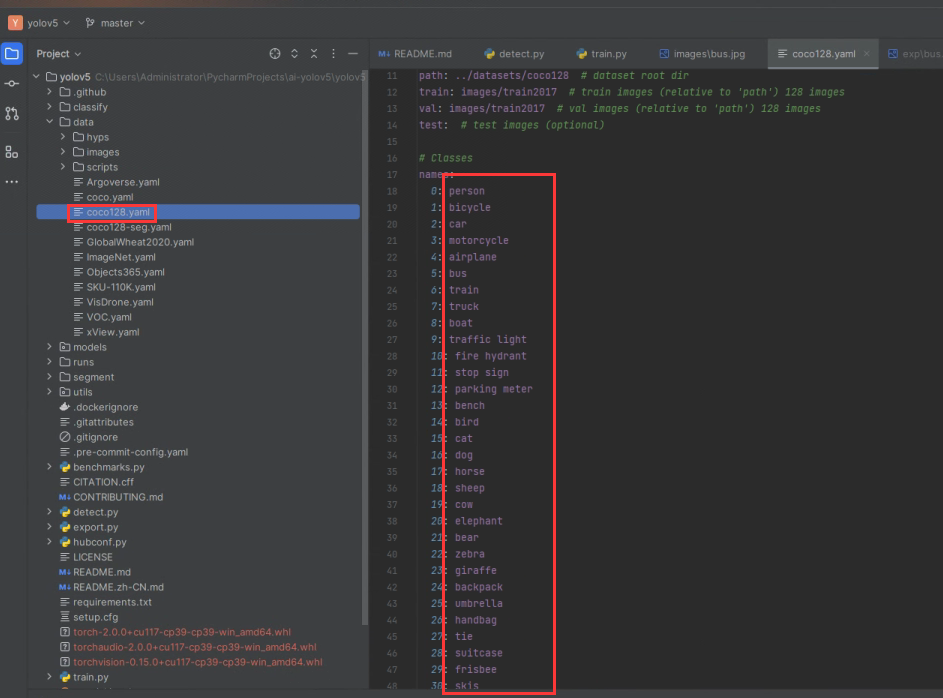
单独新建一个classes.txt文件,将coco128.yaml中已有的类别都放进去,如下图所示。
我们将这个classes.txt复制在coco128的作为一个predefined_class.es.txt(预定义的类别文件,后面会说这个文件的作用)
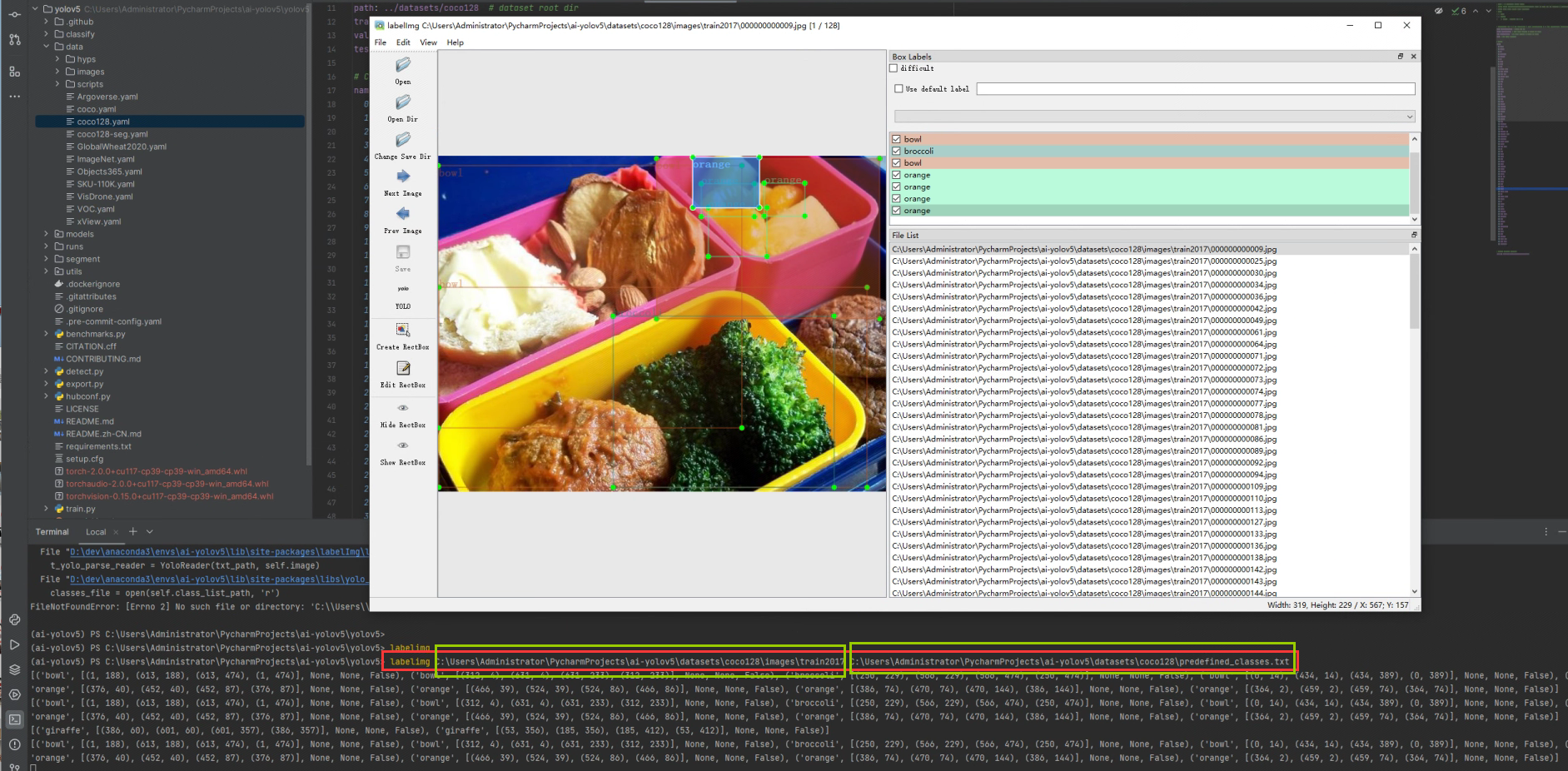
再使用以下命令去启动labelimg。
labelimg C:\Users\Administrator\PycharmProjects\ai-yolov5\datasets\coco128\images\train2017 C:\Users\Administrator\PycharmProjects\ai-yolov5\datasets\coco128\predefined_classes.txt
其中第一个参数为图片路径,第二个参数为predefined_classes.txt的路径,打开labelimg后再选择change save dir就可以看到被方框标注过的图片显示出来了。
2)标签工具的基本操作
我们基于刚刚打开的coco128进行标签的操作。
选中一个标签->右键->Delete Rectbox或直接使用键盘上的Delete按键来删除一个标签,我现在把这个图片的所有标签删除。
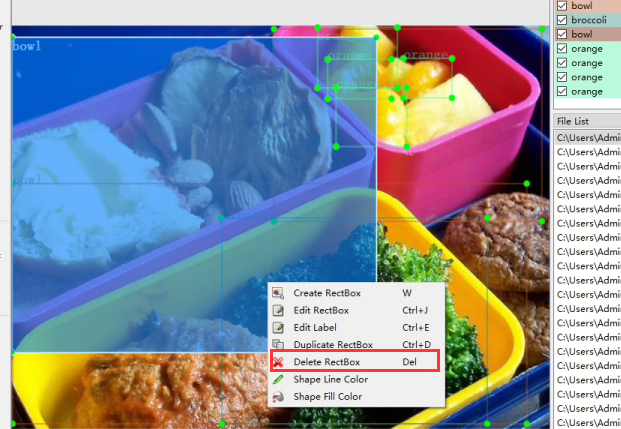
重新的对橙子打上一个orange标签,点击Create RectBox,会将你的鼠标变成一个十字准星,按下左键拖拽即可创建一个标签框。
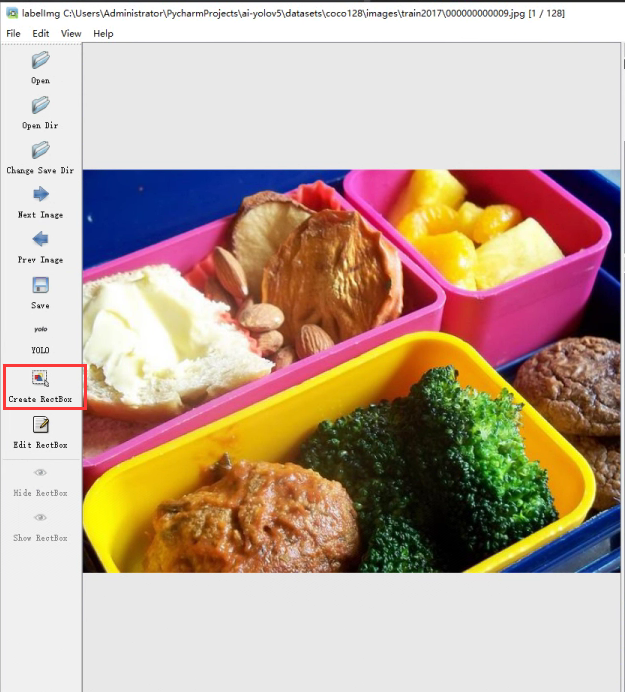
框中橙子,选择orange标签(这里下拉框所选择的标签,就是predefined_classes.txt中的内容,所以这个文件比较重要),这个时候一个橙子就被标记好了。按下ctrl+s就能保存该图片的标注文件。
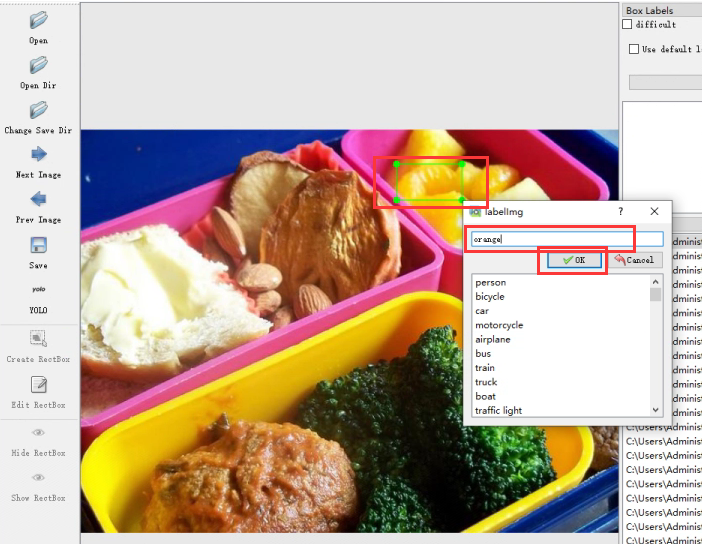
保存成功后,点击Next Image就是下一张,点击Prev Image就是上一张。
注意:在标记新文件时,记得要将格式切换成YOLO,点击红框会切换格式,一直点击到显示为YOLO为止。
至此,你已经成功安装labelimg并学习了labelimg的使用了
3、使用自定义数据集训练模型
本文针对apex的人物标记做模型训练,在yolov5/data文件下新建apex.yaml(这个可以自己命名),以下为配置文件内容(需要根据自己的数据集位置做变更)
path: ./apex_model/1w2 # dataset root dir
train: images/train
val: images/val
test: images/test
nc: 3
names:
0: 'enemy'
1: 'team'
2: 'through'
其中:
- path:数据集的根目录
- train:训练集与path的相对路径
- val:验证集与path的相对路径
- test:测试集与path的相对路径
- nc:类别数量,基于你的predefined_classes.txt的类别数量
- names:类别名字,用于验证后的标注方框的命名。可以往上回忆bus.jpg验证的图片内容。
例:像在项目的相对目录的数据集,使用./apex_model/1w2
train,val,test使用数据集的相对目录。
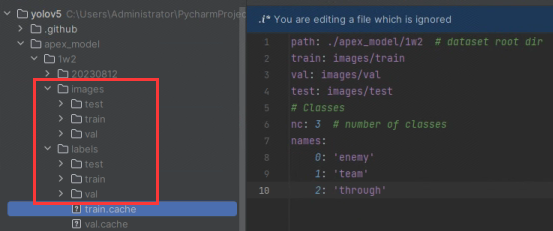
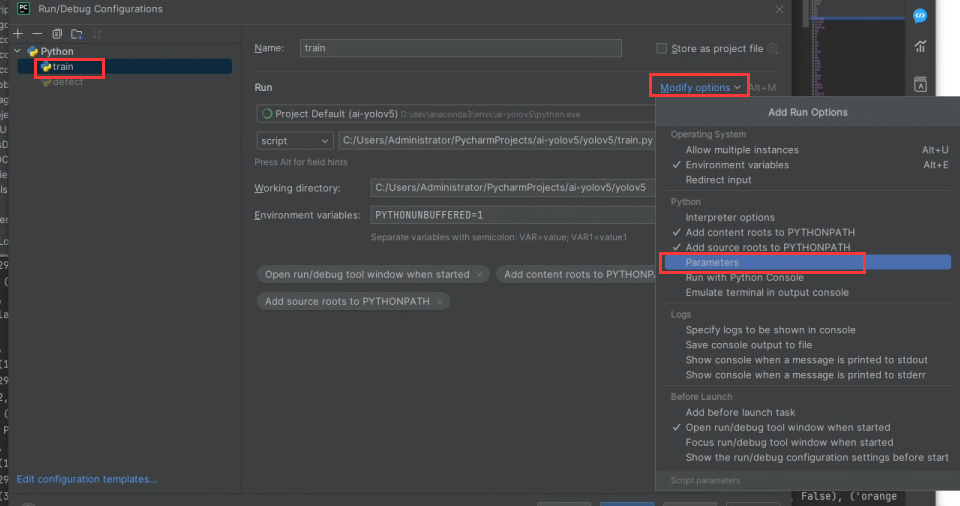
配置文件确定好了以后,基于以下train命令启动参数,编辑pycharm的train的启动参数,如果直接使用终端命令行可以忽略pycharm的配置。
python train.py --weights --data .\apex_model\1w2\1w.yaml --workers 8 --batch-size 16
pycharm配置train的启动参数

勾选Parameters,在Parameters框中填入
--data 后面使用你的配置文件
--workers 与 --batch-size根据自己的cpu和gpu核心来设置。可以不填使用默认配置。
更多参数请参考该链接
--weights --data .\apex_model\1w2\1w.yaml --workers 8 --batch-size 16
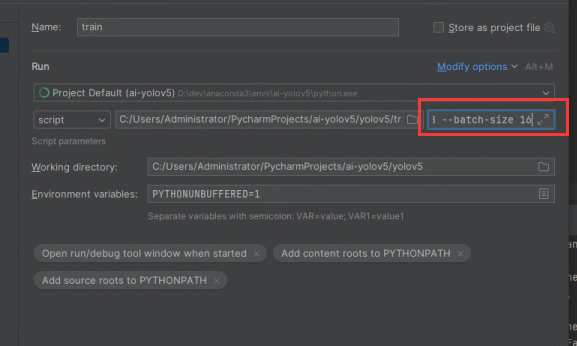
保存后,运行train即可使用你的数据集进行训练模型。与前文所说,在日志中会打印出last.pt和best.pt文件所在位置,我们最后会在运行detect时选择使用best.pt这个文件进行验证。
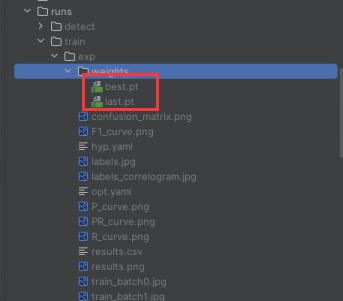
本文将生成的best.pt复制到apex_model下重命名为apex.pt(这一步按照自身需要来做变更)
使用R99.mp4这个录像来进行验证
在终端中输入
python detect.py --imgsz 640 --data .\apex_model\1w2\1w.yaml --weights .\apex_model\apex.pt --source .\data\images\R99.mp4
执行完毕后,会打印验证结果的路径
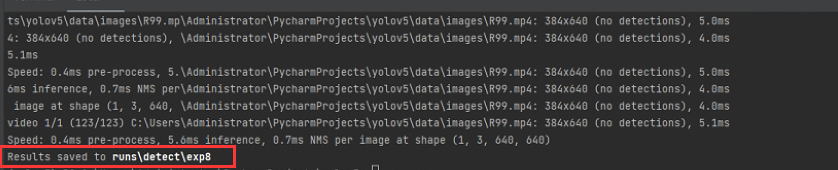
看到输出了一个同样的R99.mp4
打开播放一下,发现视频里的人物都被标记了框

这就说明了利用你自己标记的数据集,来生成的pt文件已经是可用的了,可以用来做下一步的模型trt加速。
4、trt加速pt模型
早在环境准备时,我们已经安装了trt了,接下来只需要使用export.py来生成engine即可。
终端运行以下命令,会在apex.pt相同目录下生成一个apex.engine
python export.py --imgsz 640 --weights .\apex_model\apex.pt --data .\apex_model\1w2\1w.yaml --include engine
在终端中输入以下命令来验证engine(其实只需要将上文的pt文件改为engine文件即可),一切照旧。
python detect.py --imgsz 640 --data .\apex_model\1w2\1w.yaml --weights .\apex_model\apex.engine --source .\data\images\R99.mp4
三、利用yolov5编写自动瞄准
1、label标注文本txt的内容含义
在我们进行计算坐标前,我们先来了解一下数据集label中的内容。
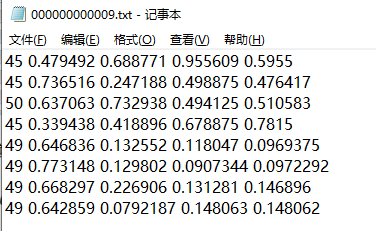
txt中存放标签数据,每一行数字分别表示:目标类别,x,y,w,h
<object-class> <x> <y> <width> <height>
例如:
45 0.479492 0.688771 0.955609 0.5955
其中
-
<object-class>:对象的标签索引(标签索引从0开始)
-
x,y是目标的中心坐标,width,height是目标的宽和高。这些坐标是通过归一化的,其中x,width是使用原图的width进行归一化;而y,height是使用原图的height进行归一化。
还原实际意义解读
这张图片中,存在一个标签框bowl
中心在(640*0.479492,480*0.688771) ≈ (307,331)
长宽为(640*0.955609,480*0.5955) ≈ (612,286)
当train时,将label作为入参进行网络训练。我们可以猜想一下当detect时会发生些什么,他是如何将image or video打上边框的,他是否会存在以标签数据相同格式的出参,换算成上以中心,长宽来在图片上画框?
其实yolo就是这么做的。接下来我们需要查看detect.py的代码。
在进行一系列的参数初始化后,来到run方法。
2、yolov5源码阅读
1) 数据准备部分
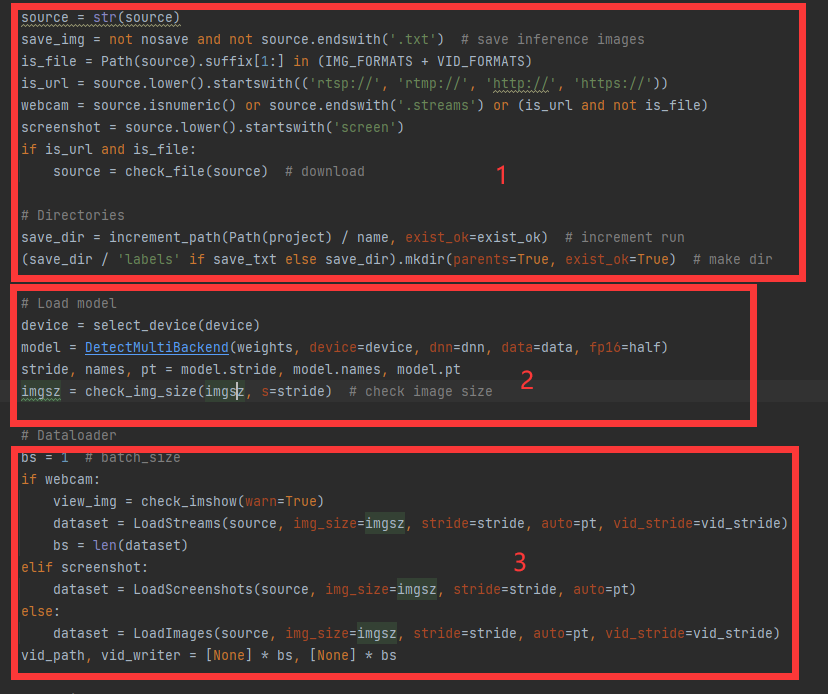
-
进行基本参数的准备,数据来源协议,是否保存结果的判断,得出保存结果路径
-
读取模型,即我们之前训练出来的engine文件的加载。
-
数据加载,我们预先设置好的网络流,截图,文件夹的数据加载类初始化。我们主要作用是用来实时抓取屏幕画面,所以看一下LoadScreenshots的实现
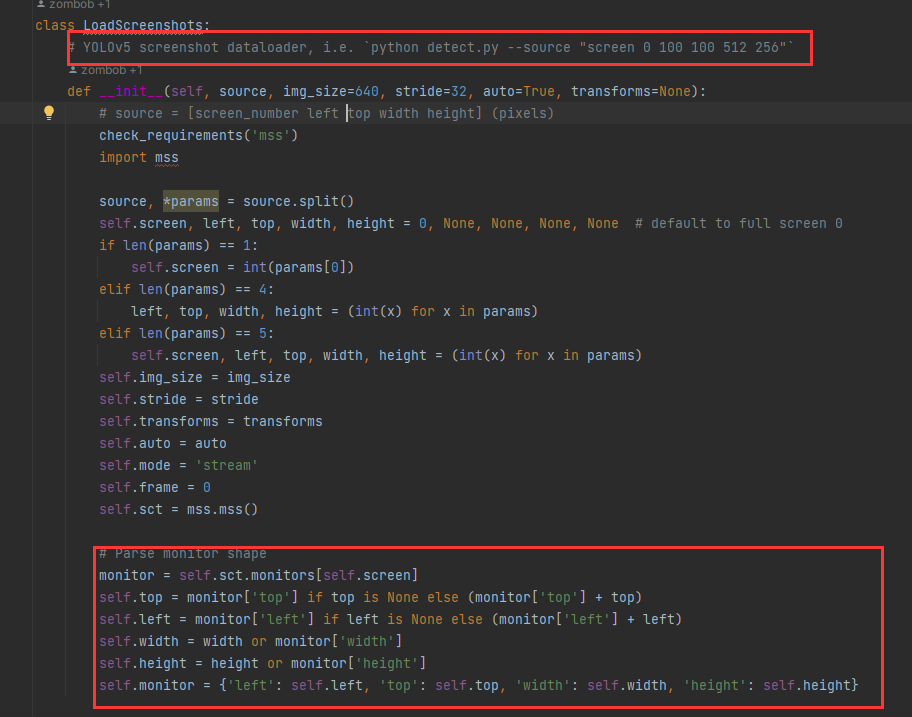
- 构造函数中读取--source的字符串切分,示例:"screen 0 100 100 512 256",然后拼装成monitor对象。
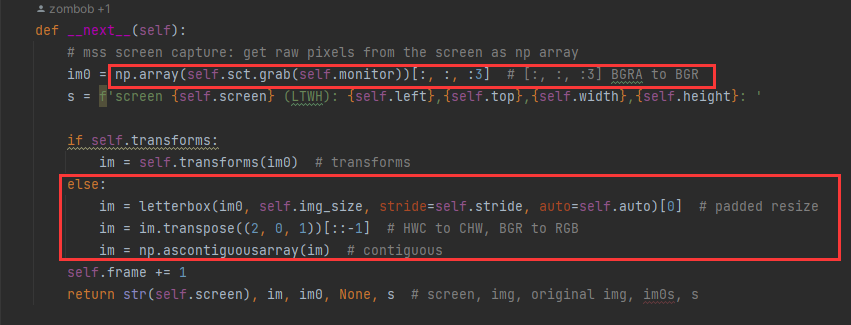
- 使用mss 从屏幕获取monitor范围内的截图转换成 np 数组。
- 将得到的任意大小的图片缩小或放大直至能填充img_size的方格内,转置颜色后,将一个该图片数组转换为内存连续存储的数组,这会使得运行速度更快,最后得到的图片im是一个byte数组。
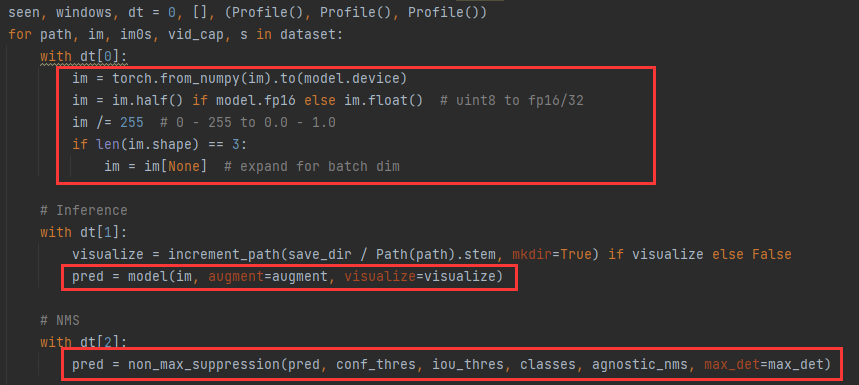
2) 模型推理部分
- 进行精度选择,图片字节归一化
- 模型推理
- 根据置信度,交并比进行非极大制抑制(NMS),得到最终的标签框。
3) 输出txt格式部分
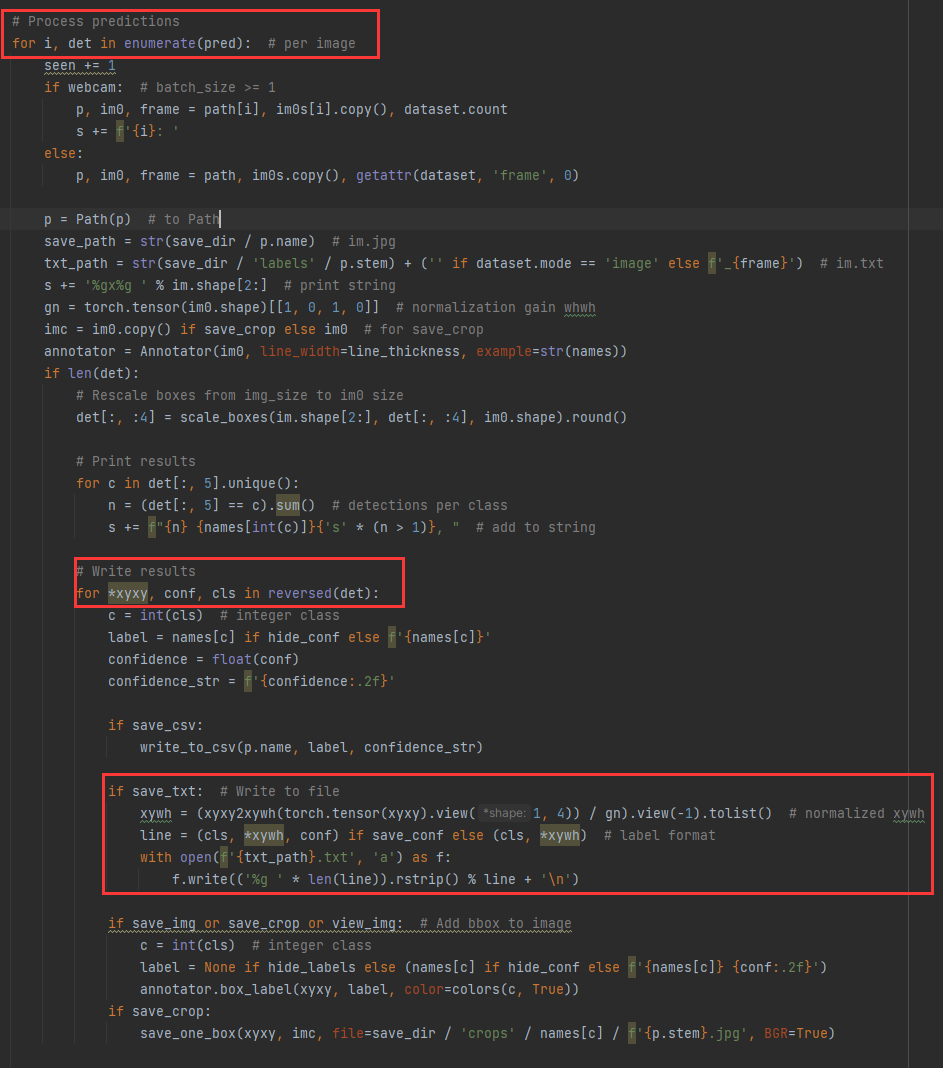
在解析推理结果中,通过解析det能得出:标签归一化坐标*xyxy,标签类别cls,save_conf默认为False,最终写入txt中的格式就恰好为<object-class> <x> <y> <width> <height>。这个就是推理出的标签在图片上的位置。
可以通过整合所有红框中的代码,使用mss截图通过已有模型推理的标签,以下为简化后的代码。
import os
import sys
import torch
from models.common import DetectMultiBackend
from utils.dataloaders import LoadScreenshots
from utils.general import check_img_size, non_max_suppression, scale_boxes, xyxy2xywh
from utils.torch_utils import select_device
from pathlib import Path
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
def run(
weights=ROOT / 'yolov5s.pt', # model path or triton URL
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride)
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
for path, im, im0s, vid_cap, s in dataset:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float()
im /= 255
if len(im.shape) == 3:
im = im[None]
pred = model(im, augment=augment, visualize=visualize)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
for i, det in enumerate(pred):
im0 = im0s.copy()
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
if len(det):
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
for *xyxy, conf, cls in reversed(det):
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
line = (cls, *xywh)
print(('%g ' * len(line)).rstrip() % line)
if __name__ == '__main__':
run(weights=Path('apex_model/apex.engine'), source="screen 0", data=Path('models/apex.yaml'))
运行以上代码,在屏幕上打开apex,并屏幕中有人物时,会打印出人物边框label信息
实际上,该例子针对实现自动瞄准时还需要被优化,当我们一张截图中有多个目标时,我们应该选取距离我们鼠标最近的目标。
编写以下方法:current_mouse_x,current_mouse_y为当前鼠标位置,shot_width,shot_heght为截图大小。
通过逆向归一化加勾股定理来筛选出距离当前鼠标位置最近的label。
def get_nearest_center_aim(aims, current_mouse_x, current_mouse_y, shot_width, shot_height):
dist_list = []
aims_copy = aims.copy()
aims_copy = [x for x in aims_copy if x[0] == 0]
if len(aims_copy) == 0:
return
for det in aims_copy:
_, x_c, y_c, _, _ = det
dist = (shot_width * float(x_c) - current_mouse_x) ** 2 + (shot_height * float(y_c) - current_mouse_y) ** 2
dist_list.append(dist)
return aims_copy[dist_list.index(min(dist_list))]
当前鼠标位置在fps游戏中,可以被当作在屏幕中心。我们可以这样来获取屏幕分辨率。
def get_resolution():
screen = tkinter.Tk()
resolution_x = screen.winfo_screenwidth()
resolution_y = screen.winfo_screenheight()
screen.destroy()
return resolution_x, resolution_y
拿到分辨率后,我们可以进行调用
aim = get_nearest_center_aim(aims, resolution_x // 2, resolution_y // 2, resolution_x, resolution_y)
修改后的总体代码如下:
import os
import sys
import tkinter
import torch
from models.common import DetectMultiBackend
from utils.dataloaders import LoadScreenshots
from utils.general import check_img_size, non_max_suppression, scale_boxes, xyxy2xywh
from utils.torch_utils import select_device
from pathlib import Path
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
def run(
weights=ROOT / 'yolov5s.pt', # model path or triton URL
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
resolution_x, resolution_y = get_resolution()
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
for path, im, im0s, vid_cap, s in dataset:
aims = []
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float()
im /= 255
if len(im.shape) == 3:
im = im[None]
pred = model(im, augment=augment, visualize=visualize)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
for i, det in enumerate(pred):
im0 = im0s.copy()
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
if len(det):
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
for *xyxy, conf, cls in reversed(det):
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
line = (cls, *xywh)
aims.append(line)
aim = get_nearest_center_aim(aims, resolution_x // 2, resolution_y // 2, resolution_x, resolution_y)
print(('%g ' * len(aim)).rstrip() % aim)
def get_nearest_center_aim(aims, current_mouse_x, current_mouse_y, shot_width, shot_height):
dist_list = []
aims_copy = aims.copy()
aims_copy = [x for x in aims_copy if x[0] == 0]
if len(aims_copy) == 0:
return
for det in aims_copy:
_, x_c, y_c, _, _ = det
dist = (shot_width * float(x_c) - current_mouse_x) ** 2 + (shot_height * float(y_c) - current_mouse_y) ** 2
dist_list.append(dist)
return aims_copy[dist_list.index(min(dist_list))]
def get_resolution():
screen = tkinter.Tk()
resolution_x = screen.winfo_screenwidth()
resolution_y = screen.winfo_screenheight()
screen.destroy()
return resolution_x, resolution_y
if __name__ == '__main__':
run(weights=Path('apex_model/apex.engine'), source="screen 0", data=Path('models/apex.yaml'))
至此,我们已经基本找到yolov5中可复用到我们程序中的推理标签位置代码。
3、缩小截图,计算坐标,移动鼠标
在本文上一小节的例子中,已经得出了可推理得到距离中心最近的标签框位置,我们拿一个label进行详细的计算鼠标偏移:
0 0.644922 0.447222 0.0195312 0.0680556
我当前分辨率为2560*1440,得到的图片尺寸与屏幕分辨率一致
计算出边框中心点x,y = 2560*0.644922,1440*0.447222 ≈ 1652,644
计算出边框大小 w,h =2560*0.0195312,1440*0.0680556 ≈ 50,98
一般我们要计算fps游戏中,鼠标移动到人物上所需要移动的x,y轴像素点时,可以默认当前鼠标在屏幕中心:
即current_x,current_y = 2560//2,1440//2 =1280,720
这样我们就能得出我们需要移动鼠标的垂直和水平像素为:move_x,move_y=1652-1280,644-720=372,-76
这只是一个简单的计算,但如果为了加快推理速度,我们截图的区域如果不是全屏,而是以准星为中心的一小片区域。我们计算出的边框信息(x,y,w,h)就会以这一区域的尺寸做逆归一化运算。得出的中心点就不能直接与屏幕中心相减了。
为了理解这一段话,我们来看图。坐标系如下所示,对于截图区域来说,屏幕的左上角为(0,0),向右向下时坐标会增加。
相同的,对于截图内的标签框来说,截图的左上角也是(0,0)。
所以我们需要先计算出标签框左上角处于屏幕的坐标,再将中心点与该坐标相加,才能得出该标签框中心在屏幕的坐标。
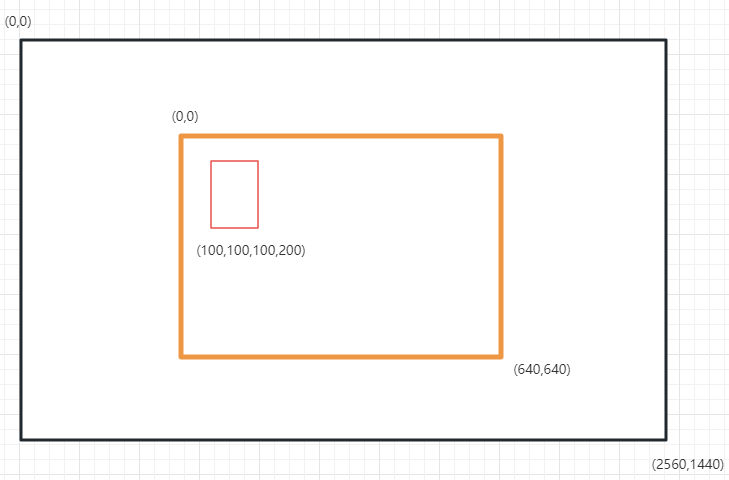
拿上图为例子,我们计算一次标签框的真实坐标,已知:
截图区域处于屏幕中心,截图区域(shot_width,shot_height)=(640,640)
屏幕分辨率为(2560,1440)
边框除于截图区域内地坐标为 (targetShotX,targetShotY)=(100,100)
截图左上角处于屏幕的坐标为 (x,y)=(current_x-shot_width/2 , current_y-shot_height/2) = 1280-320,720-320= (960,400)
边框中心处于屏幕的坐标 (targetRealX,targetRealY) = (960+100,400+100) =(1060,500)
这样我们就能得出我们需要移动鼠标的垂直和水平像素为:(move_x,move_y)=(1060-1280,500-720)=(-220,-220)
修改后的代码如下,通过calculate_mouse_offset函数计算了鼠标移动偏移,再使用win32api移动鼠标到指定位置
import os
import sys
import tkinter
from ctypes import windll
import torch
from models.common import DetectMultiBackend
from utils.dataloaders import LoadScreenshots
from utils.general import check_img_size, non_max_suppression, scale_boxes, xyxy2xywh
from utils.torch_utils import select_device
from pathlib import Path
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
def run(
weights=ROOT / 'yolov5s.pt', # model path or triton URL
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
resolution_x, resolution_y = get_resolution()
shot_width, shot_height = imgsz
left_top_x, left_top_y = (resolution_x // 2 - shot_width // 2, resolution_y // 2 - shot_height // 2) # 截图框的左上角坐标
source = f"screen 0 {left_top_x} {left_top_y} {shot_width} {shot_height}"
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
user32 = windll.user32
for path, im, im0s, vid_cap, s in dataset:
aims = []
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float()
im /= 255
if len(im.shape) == 3:
im = im[None]
pred = model(im, augment=augment, visualize=visualize)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
for i, det in enumerate(pred):
im0 = im0s.copy()
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
if len(det):
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
for *xyxy, conf, cls in reversed(det):
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
line = (cls, *xywh)
aims.append(line)
aim = get_nearest_center_aim(aims, resolution_x // 2, resolution_y // 2, shot_width, shot_height)
print(('%g ' * len(aim)).rstrip() % aim)
move_x, move_y = calculate_mouse_offset(aim, resolution_x, resolution_y, left_top_x, left_top_y, shot_width,shot_height)
user32.mouse_event(0x1, move_x, move_y) #移动鼠标
def get_nearest_center_aim(aims, current_mouse_x, current_mouse_y, shot_width, shot_height):
"""筛选离鼠标最近的label"""
dist_list = []
aims_copy = aims.copy()
aims_copy = [x for x in aims_copy if x[0] == 0]
if len(aims_copy) == 0:
return
for det in aims_copy:
_, x_c, y_c, _, _ = det
dist = (shot_width * float(x_c) - current_mouse_x) ** 2 + (shot_height * float(y_c) - current_mouse_y) ** 2
dist_list.append(dist)
return aims_copy[dist_list.index(min(dist_list))]
def get_resolution():
"""获取屏幕分辨率"""
screen = tkinter.Tk()
resolution_x = screen.winfo_screenwidth()
resolution_y = screen.winfo_screenheight()
screen.destroy()
return resolution_x, resolution_y
def calculate_mouse_offset(aim, resolution_x, resolution_y, left_top_x, left_top_y, shot_width, shot_height):
"""计算鼠标偏移"""
tag, target_x, target_y, target_width, target_height = aim
target_shot_x = shot_width * float(target_x) # 目标在截图范围内的坐标
target_shot_y = shot_height * float(target_y)
screen_center_x = resolution_x // 2
screen_center_y = resolution_y // 2
target_real_x = left_top_x + target_shot_x # 目标在屏幕的坐标
target_real_y = left_top_y + target_shot_y
return int(target_real_x - screen_center_x), int(target_real_y - screen_center_y)
if __name__ == '__main__':
run(weights=Path('apex_model/apex.engine'), data=Path('models/apex.yaml'))
至此,你已经编写了一个完整的自动瞄准例子了。
四、拟人移动鼠标
在上章的例子中,我们的鼠标是瞬间移动到偏移中的,这种反人类的鼠标移动方式(简称一帧拉枪),这种移动方式必然逃不过游戏中的行为检测。
我们需要植入更像人类的移动鼠标的方式,在通过研究上报率为1000时的罗技鼠标移动轨迹时,发现鼠标移动幅度为1。即如果需要移动偏移量为(5,3)时,会分成以下5组移动。
[(1,1),(1,1),(1,1),(1,0),(1,0)]
所以可以认为,在移动鼠标时,将移动的偏移量切分为每1ms移动1像素来移动。但如果这样移动会造成移动延迟,并且降低了ai识别效率。所以这里将鼠标移动分为了两步。
- 鼠标移动意图
- 鼠标真实移动过程
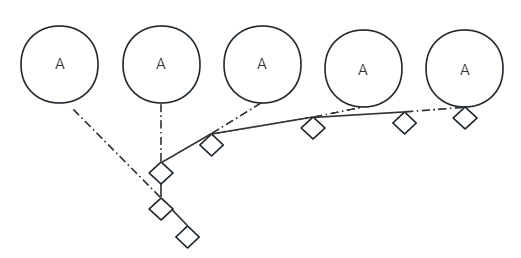
另外开启一个线程运行鼠标移动器,在推理出鼠标偏移时,将偏移(x,y)发送给鼠标移动器,作为鼠标移动意图(intention)。这个鼠标移动器在线程中进行切分移动,为了解决意图过期,在移动的过程中不断更新移动意图。
看下图,A的移动相当于每次更新意图的坐标。A在每一次移动时都进行了位置变更,我们的鼠标移动器也会在每次移动之前将目标位置进行变更,就会出现图中的随机曲线。这种处理鼠标的移动方式将会更加平滑与随机。
一般来说,鼠标都是能够跟上A的移动的,这里只是夸大的抽象表达了鼠标移动曲线的随机性。
以下是鼠标移动器的代码实现
import time
from ctypes import windll
class Win32ApiMouseMover:
def __init__(self, move_step=1, move_frequency=0.001):
self.intention = None
self.change_coordinates_num = 0
self.user32 = windll.user32
self.move_step = move_step
self.move_frequency = move_frequency
def set_intention(self, move_x, move_y):
"""设置移动意图"""
self.intention = move_x, move_y
self.change_coordinates_num += 1
def start(self):
"""启动鼠标移动器"""
print("win32api鼠标移动器启动")
while True:
if self.intention is not None:
t0 = time.time()
(x, y) = self.intention
print("开始移动,移动距离:{}".format((x, y)))
while x != 0 or y != 0:
(x, y) = self.intention
move_up = min(self.move_step, abs(x)) * (1 if x > 0 else -1)
move_down = min(self.move_step, abs(y)) * (1 if y > 0 else -1)
if x == 0:
move_up = 0
elif y == 0:
move_down = 0
x -= move_up
y -= move_down
self.intention = (x, y)
self.user32.mouse_event(0x1, int(move_up), int(move_down))
time.sleep(0.001)
print(
"完成移动时间:{:.2f}ms,坐标变更次数:{}".format((time.time() - t0) * 1000,
self.change_coordinates_num))
self.intention = None
self.change_coordinates_num = 0
time.sleep(self.move_frequency)
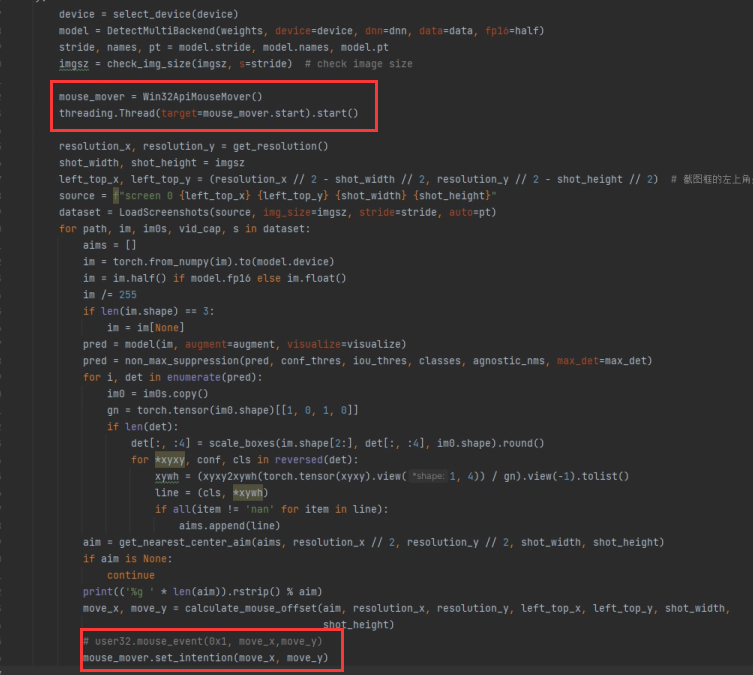
添加鼠标移动线程的启动,并将原代码的直接鼠标移动变更成设置移动意图即可
mouse_mover = Win32ApiMouseMover()
threading.Thread(target=mouse_mover.start).start()
五、双机架构
由于每个人的采集卡,模拟键鼠设备不同,当前篇幅也有限,本章主要介绍架构和设备接入,不会写的太完善。
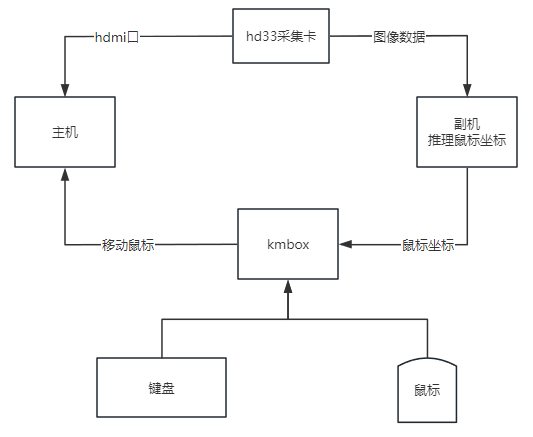
上图为双机架构,本质是通过hdmi采集卡采集显卡图像,传输到副机由副机的显卡推理label转换成坐标,控制一个模拟鼠标的硬件,通过外部硬件来移动主机的鼠标,就像真的是人在移动鼠标一样。
这个方法能绕过大部分游戏的外挂进程检测。对于主机来说,无三方软件侵入,无鼠标驱动等优点。
基本可以认为,在上图中,hd33采集卡相当于人的眼睛,副机是人的大脑,kmbox相当于人的手。
1、通过hd33采集卡采集图像
我用的这个采集卡是入门级的,比较便宜,hd33采集卡,只支持1920*1080 60hz


前面有两个hdmi口,支持环出,后面有type-c接口,支持type-c转usb。如何理解环出,请看下图。
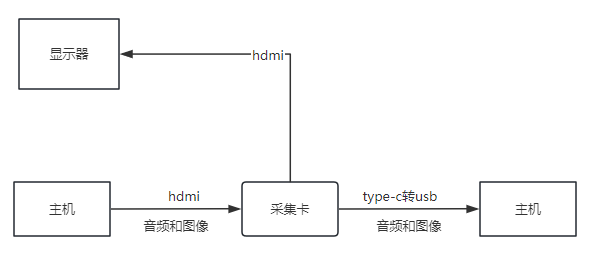
主机的hdmi的音频和图像数据到达采集卡后,采集卡会原封不动的再传输给显示器,然后复制一份到副机上。这样在主机上就只需要接一条hdmi线,系统管理的显示的也只有一台显示器。弊端就是hdmi环出刷新率低,并且dp线没法做环出,只能使用系统的屏幕复制功能。
采集卡会被当作usb摄像头来采集图像,接入代码如下。
cap = cv2.VideoCapture(0) # 视频流
cap.set(cv2.CAP_PROP_FRAME_WIDTH, global_config.screen_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, global_config.screen_height)
def get_img_from_cap(monitor):
ret, frame = cap.read()
frame = frame[monitor["top"]:monitor["top"] + monitor["height"], monitor["left"]:monitor["left"] + monitor["width"]]
return frame
2、通过kmbox移动鼠标
我手上暂时只有kmbox A板,感兴趣的同学可以自己去找B或B pro对接,A板长下面这个样子。两头usb,一头接鼠标,一头接电脑。像大板的话会有4个usb插口,能串连键盘和鼠标,并且能连副机。

可以通过封装好的dll来操作硬件控制鼠标,购买板子后,卖家会连同dll的源码也分享出来。
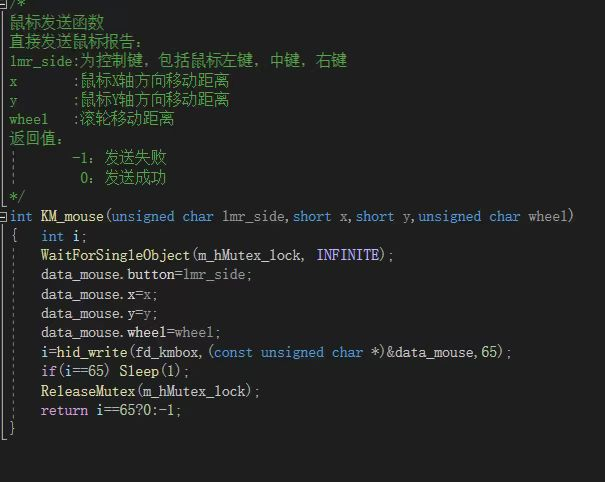
kmbox操作也比较简单,接入dll后使用api即可。
class KeyMouseSimulation():
# 初始化
# dll地址
kmboxA = ctypes.cdll.LoadLibrary(r".\kmbox_dll_64bit.dll")
kmboxA.KM_init.argtypes = [ctypes.c_ushort, ctypes.c_ushort]
kmboxA.KM_init.restype = ctypes.c_ushort
kmboxA.KM_move.argtypes = [ctypes.c_short, ctypes.c_short]
kmboxA.KM_move.restype = ctypes.c_int
def __init__(self, id):
vid = int(id[:4], 16)
pid = int(id[4:], 16)
# 连接kmbox_VER a
ts = KeyMouseSimulation.kmboxA.KM_init(ctypes.c_ushort(vid), ctypes.c_ushort(pid))
print("初始化:{}".format(ts))
def move(self, short_x: int, short_y: int):
KeyMouseSimulation.kmboxA.KM_move(short_x, short_y)

